Assamese Text-to-Speech Model Development
Introduction
The text-to-speech (TTS) system takes written words as input and converts them into audio. TTS can help anyone who is too lazy to read a news article, wants to know the pronunciation of a word, is interested in developing human-like conversational agents, etc.
The Assam AI Initiative, in collaboration with team Xobdo, has developed an Assamese text-to-speech (TTS) or speech synthesizer model. This endeavor aims to enrich the digital landscape of the Assamese language by providing a robust Assamese TTS solution. The first version of the model is now hosted on the Xobdo Xobdo Boroxa 1.0, accessible for general use, seeking feedback on pronunciation and speech quality.
Data collection and preparation
For v1.0, we have collected around 1740 sentences from different articles/stories available on different websites. And then we have done some cleaning process, such as correcting the spelling, removing very short sentences, whitespace characters, and keeping more sentences with punctuation. A few examples of sentences we used in the training are listed below:
- অংকুৰিত বুট, মগু আদি আমাৰ স্বাস্থ্যৰ পক্ষে অতি লাভজনক.
- অসমীয়া ভাষা, অসমীয়া মাধ্যমটোৰ ওপৰত আপোনাৰ মতামত কেনেকুৱা?
- আজৰি সময়ত প্রার্থনা, বিয়ানাম মুখস্থ কৰিছিলোঁ, কিতাপ পিিছিলোঁ, কৌতুক কবলৈ শিকিছিলোঁ.
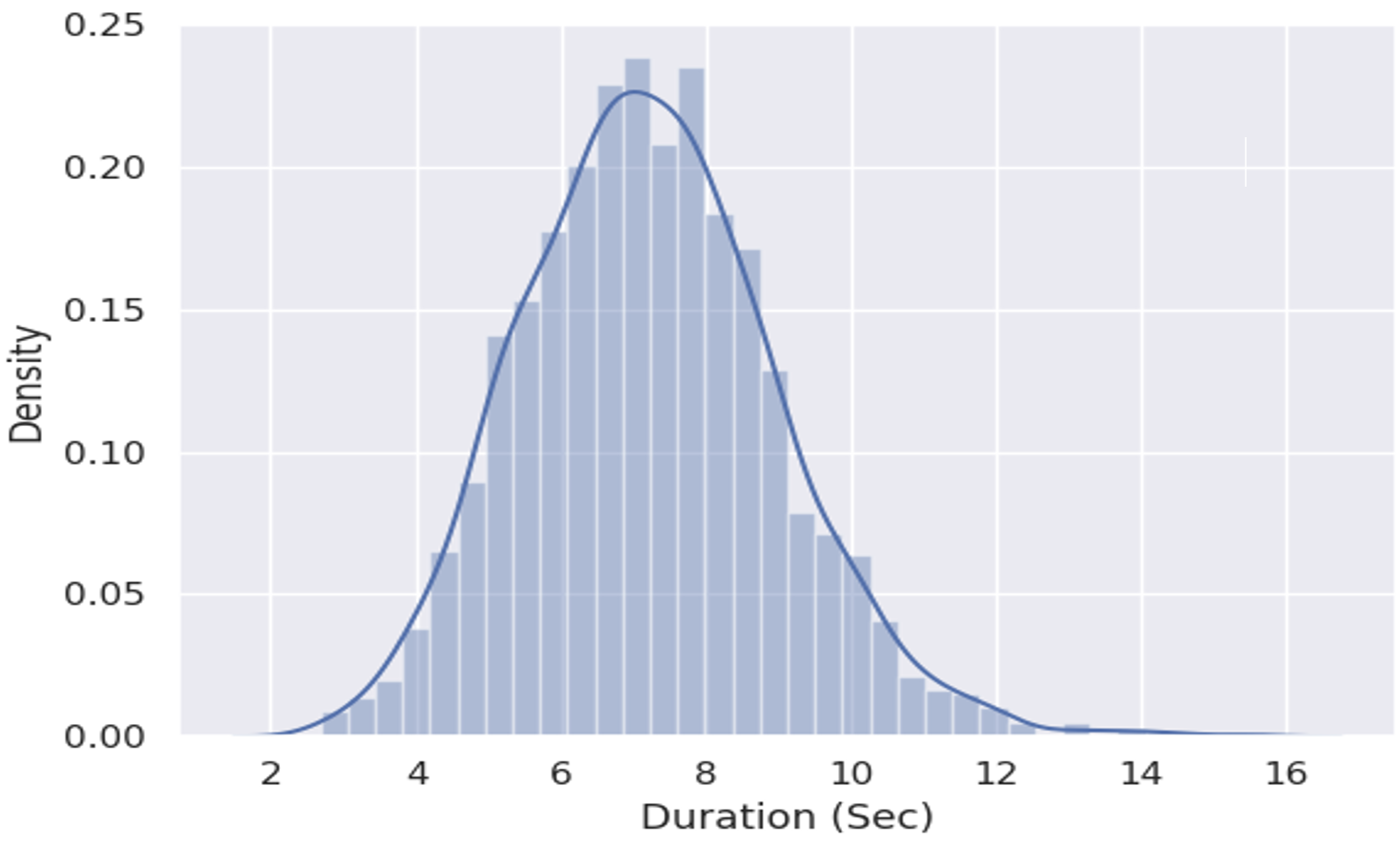
We recorded approximately 3 hours of high-quality Assamese speech data. Ensuring the purity and clarity of the dataset, each recording underwent a rigorous manual cleaning process, such as speech enhancement (using Audacity), removing bad articulated words and sentences, thereby enhancing the overall quality of the training data. Figure 1 displays the dataset’s duration distribution.
Data Augmentation: Volume Perturbation
To augment our dataset, we employed a technique known as volume perturbation. This method involves varying the volume of the audio samples, creating multiple versions of the same recording at different volume levels.
TTS model development
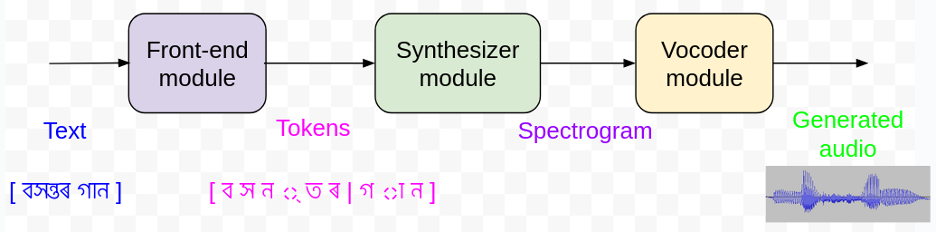
A typical neural TTS model has three components, namely, a front-end module, a synthesizer, and a vocoder. The following diagram shows a simplistic representation of the TTS system.
Model Development
Our TTS model architecture has three pivotal components: 1. A front-end module, which takes the text and preprocesses and converts the text into a sequence of tokens; 2. a synthesizer module, which takes the text input and converts it to an intermediate representation, called a spectrogram; and 3. a vocoder, which takes the spectrogram as an input and generates the corresponding audio.
Front-end module:
The front-end module takes the text string and does some preprocessing, such as converting it to utf-8, removing unnecessary special characters (currently we are allowing only “.”, “,”, “!”, and “?”), and adding word boundaries. Next, we transform the processed word sequence into a series of tokens. Here, we have used character-level tokenization for simplicity.
Synthesizer training
We first trained the Tacotron2 model, an advanced neural network architecture designed for speech synthesis. Tacotron2 converts textual input into the Mel-spectrogram, serving as an intermediate representation before waveform generation. The Tacotron2 model played a crucial role in training the subsequent Fastspeech2 model. We used the ESPnet framework for the implementation of both the Tacotron2 and Fastspeech2 models.
Vocoder training
We trained the Parallel WaveGAN (https://arxiv.org/pdf/1910.11480.pdf) for its better audio quality. We trained the model using the PyTorch implementation of Parallel WaveGAN (https://github.com/kan-bayashi/ParallelWaveGAN). This is a non-autoregressive waveform generation technique developed using the generative adversarial network (GAN). However, this model is relatively slower, and in the next version, we will explore faster waveform generation models, such as multi-band MelGAN, for faster response.
Deployment and accessibility
We deployed our TTS model using FastAPI, a modern, fast web framework for building APIs with Python. We host the model on Amazon Web Services (AWS) to ensure efficient access for users. We make API calls from the Xobdo site based on the user request and return the generated audio.
Conclusion
We encourage users to interact with the Xobdo site’s synthesizer, offering feedback to enhance the speech quality. After generating the audio, there is one form to submit feedback or suggestions. Feel free to try any Assamese sentence :)
Link for Assamese TTS: http://www.xobdo.org/boroxa/